Estymator jądrowy gęstości
Estymator jądrowy gęstości[1] lub jądrowy estymator gęstości[2] – rodzaj estymatora nieparametrycznego, przeznaczony do wyznaczania gęstości rozkładu zmiennej losowej, na podstawie uzyskanej próby, czyli wartości jakie badana zmienna przyjęła w trakcie dotychczasowych pomiarów[3].
Badana zmienna losowa może być jedno- lub wielowymiarowa. Przynależność do grupy metod nieparametrycznych oznacza, że przy ich stosowaniu nie jest wymagana a priori informacja o typie występującego rozkładu (np. czy jest on normalny, czy Cauchy’ego itp.). Klasyczne parametryczne metody estymacji gęstości wymagały wcześniejszego ustalenia takiego typu, po czym – w ramach ich stosowania – jedynie wyznaczano wartości istniejących w jego definicji parametrów.
Najprostszym nieparametrycznym estymatorem gęstości jest histogram. Estymator jądrowy w pewnym stopniu przypomina odpowiednio wygładzony wykres histogramu o małej szerokości cel.
Estymator jądrowy gęstości jest często używany do analizy danych w licznych dziedzinach nauki i zagadnień praktycznych, zwłaszcza z zakresu technik informacyjnych, automatyki, zarządzania oraz wspomagania decyzji itp.[1][4][5]
Definicja
Niech dana będzie -wymiarowa zmienna losowa której rozkład posiada gęstość Jej estymator jądrowy wyznacza się w oparciu o wartości -elementowej próby losowej





(1) |

uzyskanej ze zmiennej X, i w swej podstawowej formie jest on definiowany wzorem
(2) |

gdzie mierzalna, symetryczna względem zera oraz posiadająca w tym punkcie słabe maksimum globalne funkcja spełnia warunek i nazywana jest jądrem, natomiast dodatni współczynnik określa się mianem parametru wygładzania.




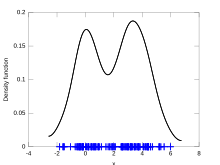
Interpretację powyższej definicji ilustruje Rys. 1, na przykładzie zmiennej losowej jednowymiarowej, czyli gdy dla 9-elementowej próby losowej, a zatem W przypadku pojedynczej realizacji funkcja (przesunięta o wektor oraz przeskalowana współczynnikiem ) reprezentuje oszacowanie rozkładu zmiennej losowej po otrzymaniu wartości Dla niezależnych realizacji oszacowanie to przyjmuje postać sumy takich pojedynczych oszacowań. Współczynnik normuje uzyskaną funkcję w celu zagwarantowania warunku wymaganego od gęstości rozkładu probabilistycznego.









Estymator jądrowy umożliwia oszacowanie gęstości praktycznie dowolnego rozkładu, bez żadnych założeń o jego przynależności do ustalonej klasy. Nietypowe, złożone rozkłady, w tym także wielomodalne, traktowane są tu tak samo jak podręcznikowe rozkłady unimodalne. W przypadku wielowymiarowym, czyli przy pozwala to między innymi na identyfikację wszechstronnych zależności pomiędzy poszczególnymi współrzędnymi badanej zmiennej losowej. Ustalenie wielkości wprowadzonych w definicji (2), a zatem wybór postaci jądra oraz wyznaczenie wartości parametru wygładzania dokonywane jest najczęściej na podstawie kryterium minimum scałkowanego błędu średniokwadratowego.


Wybór postaci jądra
Ze statystycznego punktu widzenia, postać jądra nie ma istotnego znaczenia i wybór funkcji może być arbitralny, uwzględniający przede wszystkim pożądane własności otrzymanego estymatora, na przykład klasę jego regularności (ciągłość, różniczkowalność itp.), przyjmowanie dodatnich wartości lub też inne cechy istotne dla konkretnego problemu, w tym zwłaszcza dogodność obliczeniową.
W przypadku jednowymiarowym jako funkcję przyjmuje się klasyczne postacie gęstości rozkładów probabilistycznych, na przykład gęstość rozkładu normalnego, Cauchy’ego, trójkątnego i inne. Najefektywniejszym w sensie kryterium błędu średniokwadratowego jest tak zwane jądro Epanecznikowa
(3) |
![{\displaystyle f(x)={\begin{cases}{\frac {3}{4}}(1-x^{2})&{\mbox{dla }}x\in [-1,1]\\0&{\mbox{dla }}x\in (-\infty ,-1)\cup (1,\infty )\end{cases}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cb5ef84e6922ceaf272948161bc4dfed33014c53)
W przypadku wielowymiarowym stosuje się dwa naturalne uogólnienia powyższej koncepcji: jądro radialne
(4) |

oraz jądro produktowe
(5) |
![{\displaystyle K(x)=K\left(\left[x_{1},x_{2},\dots ,x_{n}\right]^{T}\right)=\mathrm {K} (x_{1})\cdot \mathrm {K} (x_{2})\cdot \ldots \cdot \mathrm {K} (x_{n}),}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2167155b67cc460de3a2380bb6b401187cfe171c)
gdzie oznacza omówione uprzednio jądro jednowymiarowe, natomiast jest dodatnią stałą, wyznaczoną tak aby spełniony był warunek



Dla dowolnie ustalonego jądra jednowymiarowego bardziej efektywne jest jądro radialne niż produktowe, lecz z aplikacyjnego punktu widzenia różnica jest nieznaczna. Fakt ten powoduje, iż w praktycznych zastosowaniach nierzadko preferuje się jądro produktowe. Poza szczególnymi zastosowaniami statystycznymi, jest ono bowiem znacznie dogodniejsze w dalszej analizie – na przykład procedury całkowania i różniczkowania jądra produktowego niewiele różnią się od przypadku jednowymiarowego. Wśród jąder radialnych najefektywniejsze jest radialne jądro Epanecznikowa, czyli definiowane zależnością (4) gdy dane jest wzorem (3). Także w rodzinie jąder produktowych, najefektywniejsze okazuje się produktowe jądro Epanecznikowa, określone przez formuły (5) oraz (3).

Możliwość znacznej elastyczności przy doborze postaci jądra stanowi istotną praktyczną zaletę, ujawniającą się proporcjonalnie do złożoności konkretnego zastosowania[1][4].
Określenie wartości parametru wygładzania
W przeciwieństwie do postaci jądra, przyjęta wartość parametru wygładzania ma istotny wpływ na jakość otrzymanego estymatora jądrowego. Zbyt mała wartość parametru powoduje pojawienie się znacznej ilości ekstremów lokalnych estymatora co jest sprzeczne z faktycznymi własnościami realnych populacji. Z drugiej strony, za duże wartości skutkują nadmiernym wygładzeniem tego estymatora, maskującym specyficzne cechy badanego rozkładu.

Opracowane zostały dogodne algorytmy umożliwiające obliczenie zbliżonej do optymalnej (z minimalnym błędem średniokwadratowym) wartości na podstawie próby losowej (1). Uniwersalną jest metoda cross-validation[6], w ramach której wyznacza się wartość realizującą minimum rzeczywistej funkcji zdefiniowanej równością

(6) |

przy czym gdzie oznacza kwadrat splotowy funkcji Dla szczególnych przypadków opracowano także szereg specjalistycznych algorytmów, przykładowo prostą i efektywną metodę plug-in stosowaną do przypadku jednowymiarowego.



Możliwość zmiany i odejście od optymalnej wartości parametru wygładzania może być wykorzystywane na przykład przy stosowaniu estymatorów jądrowych do zagadnień eksploracji danych, między innymi w procedurach klasteryzacji do wpływania na potencjalną liczbę skupień[7].
Dodatkowe uwagi i komentarze
Zaprezentowana powyżej podstawowa postać estymatora jądrowego (2) może być w praktyce uogólniona w celu generalnej poprawy jego własności oraz ewentualnie uzupełniana o dodatkowe aspekty dopasowujące model do badanej rzeczywistości.
Uogólnienie może przyjąć np. formę transformacji liniowej i modyfikacji parametru wygładzania, natomiast uzupełnienie może obejmować ograniczenie nośnika estymatora oraz uwzględnienie współrzędnych binarnych i skategoryzowanych.
Transformacja liniowa
Transformacja liniowa jest raczej typowa dla analizy wielowymiarowych danych. Dzięki niej macierz kowariancji staje się jednostkowa, co znacznie uproszcza interpretację zarówno poszczególnych współrzędnych, jak i ich współzależności.
Modyfikacja parametru wygładzania
W zagadnieniach aplikacyjnych, jakość estymatora jądrowego można zwiększyć stosując tzw. modyfikację parametru wygładzania. Powoduje ona, że w rejonach „zagęszczenia” elementów próby losowej poszczególne jądra ulegają „wyszczupleniu” (co pozwala lepiej uwidoczniać specyficzne cechy rozkładu), w przeciwieństwie do obszarów, w których elementy te są „rzadkie” gdzie jądra ulegają spłaszczeniu (co m.in. powoduje dodatkowe „wygładzenie” tzw. „ogonów”). Intensywność działania tej procedury ustalana jest pojedynczym parametrem, którego zmiana wartości daje istotne i nietrywialne możliwości w złożonych procedurach analizy i eksploracji danych. Co więcej, modyfikacja parametru wygładzania zmniejsza różnicę efektywności poszczególnych typów jąder względem optymalnego jądra Epanecznikowa (3), podobnie jak w przypadku wielowymiarowym zmniejsza różnicę efektywności jądra produktowego (5) względem radialnego (4).
Powyższe własności są cenne w praktycznych zastosowaniach, gdyż dodatkowo zwiększają możliwość preferencji jąder korzystnych dla dalszej analizy w konkretnych zadaniach aplikacyjnych.
Wymagana liczność próby
Niezbędna liczność próby (wzór (1)) zależy przede wszystkim od wymiaru badanej zmiennej losowej. W celu zapewnienia 10-procentowej dokładności w punkcie zero dla -wymiarowego standardowego rozkładu normalnego można w przybliżeniu przyjąć jako Ze względu na szczególną regularność powyższego rozkładu oraz znaczny liberalizm przyjętego kryterium, wartości te wydają się stanowić bezwzględne minimum (sugeruje to na przykład dla ).



W praktyce uzyskany wynik mnoży się przez heurystycznie określane współczynniki związane z koniecznością polepszenia jakości estymacji, wielomodalnością i niesymetrią rozkładu oraz korelacją elementów próby losowej. Iloczyn tych współczynników osiąga najczęściej wartości z przedziału 3-10, ale w ekstremalnych przypadkach nawet 100.
Dla jednowymiarowej zmiennej losowej, wymagana liczność próby wynosi w praktyce 20-50, odpowiednio zwiększając się wraz ze wzrostem wymiaru zmiennej. Jednak dzięki współczesnej technice komputerowej, nawet w złożonych zagadnieniach wielowymiarowych i przy niesprzyjających cechach rozkładów, nie musi to obecnie stanowić istotnej przeszkody aplikacyjnej, zwłaszcza dzięki możliwościom stosowania procedur redukcji wymiaru i liczności próby Zawsze należy bowiem brać pod uwagę znaczące korzyści wynikające ze stosowania estymatorów jądrowych. Umożliwiają one bowiem identyfikację praktycznie dowolnego występującego w zadaniach aplikacyjnych rozkładu, aczkolwiek wymagają stosownej liczności próby, adekwatnej do mnogości i wszechstronności zawartej w nich informacji.

Zastosowania do zagadnień pokrewnych
Dogodna postać estymatorów jądrowych i łatwość ich interpretacji umożliwia użyteczne uogólnienia oraz zmiany dogodne z punktu widzenia konkretnego zadania. Przykładowo, podstawową postać (2) można uzupełnić o nieujemne, nie wszystkie równe zeru współczynniki przy które interpretuje się jako znaczenie lub reprezentatywność poszczególnych elementów próby losowej (1). Wtedy:


(7) |

Odpowiedni dobór wartości parametrów umożliwia znaczące polepszenie wyników analizy danych, na przykład w zagadnieniu klasyfikacji.
Estymator jądrowy gęstości może być także podstawą do wyznaczenia innych charakterystyk funkcyjnych oraz parametrów. Na przykład jeśli w przypadku jednowymiarowym zostanie wybrane takie jądro aby istniała analityczna postać jego pierwotnej to zdefiniować można estymator dystrybuanty


(8) |

Z kolei jeżeli jądro ma dodatnie wartości, to rozwiązanie równania
(9) |

stanowi jądrowy estymator kwantyla stopnia


Analogicznie do estymatora gęstości rozkładu zmiennej losowej, formułowana jest koncepcja jądrowego estymatora gęstości widmowej, a także jądrowego estymatora funkcji regresji. Zgodnie z generalną zasadą estymatorów jądrowych, funkcja ta jest wyznaczana bez założeń arbitralnie ustalających jej postać, na przykład jako liniową lub logarytmiczną.
Zobacz też
Przypisy
- ↑ a b c P. Kulczycki, Estymatory jądrowe w zagadnieniach badań systemowych (rozdział w: P. Kulczycki, O. Hryniewicz, J. Kacprzyk (red.), Techniki informacyjne w badaniach systemowych, WNT, Warszawa 2007).
- ↑ Bartłomiej Stępień, Estymacja niepewności wskaźników zagrożeń hałasowych środowiska, rozprawa doktorska, Akademia Górniczo-Hutnicza im. Stanisława Staszica, Kraków 2010.
- ↑ Używając coraz częściej ostatnio stosowanej nomenklatury analizy danych można równoważnie stwierdzić: rozkładu cechy populacji na podstawie zaobserwowanych jej wartości.
- ↑ a b P. Kulczycki, Kernel Estimators in Industrial Applications (rozdział w: B. Prasad (red.), „Soft Computing Applications in Industry”, Springer-Verlag, Berlin 2008).
- ↑ P. Kulczycki, Applicational Possibilities of Nonparametric Estimation of Distribution Density for Control Engineering, „Bulletin of the Polish Academy of Sciences: Technical Sciences”, Vol. 17, 2008.
- ↑ D.W. Scott, G.R. Terrell, Biased and unbiased cross-Validation in density estimation, „Journal of the American Statistical Association”, Vol. 82 (400), 1987.
- ↑ P. Kulczycki, M. Charytanowicz, P.A. Kowalski, S. Łukasik, The Complete Gradient Clustering Algorithm: Properties in Practical Applications, „Journal of Applied Statistics”, Vol. 39, 2012.
Bibliografia
- Kulczycki P., Estymatory jądrowe w analizie systemowej, WNT, Warszawa 2005.
- Kulczycki P., Hryniewicz O., Kacprzyk J. (red.), Techniki informacyjne w badaniach systemowych, WNT, Warszawa 2007.
- Silverman B.W., Density Estimation for Statistics and Data Analysis, Chapman and Hall, London 1986.
- Wand M.P., Jones M.C., Kernel Smoothing. Chapman and Hall, London 1994.
- Wasserman L., All of Nonparametric Statistics, Springer, New York 2007.











