Empirická distribuční funkce



Empirická distribuční funkce (obvykle označovaná eCDF podle anglického empirical Cumulative Distribution Function) je ve statistice distribuční funkce vytvořená na základě empirické míry určené hodnotami určitého znaku z výběrového souboru.[1] Tato distribuční funkce je schodovitá funkce tvořená skoky velikosti 1/n v každém z n datových bodů. Její hodnota v každém bodě je zlomek, jehož čitatelem je počet pozorování, v nichž je měřená proměnná menší nebo rovna zadané hodnotě, a jmenovatelem je rozsah souboru, N.
Empirická distribuční funkce je odhadem distribuční funkce, která generuje datové body. Podle Glivenkovy–Cantelliho věty konverguje k tomuto podkladovému rozdělení s pravděpodobností 1. Rychlost konvergence empirické distribuční funkce k podkladové distribuční funkci popisují různé matematické věty.
Definice
Nechť (X1, …, Xn) jsou nezávislé stejně rozdělené náhodné veličiny reálné náhodné proměnné se stejnou distribuční funkcí F(t). Empirická distribuční funkce je pak definována vzorcem[2][3]

kde je počet prvků, které mají hodnotu zvoleného znaku menší nebo rovnou , je charakteristická funkce události A. Pro pevné t je indikátor náhodná proměnná s Bernoulliho rozdělením s parametrem p = F(t); tedy je binomická náhodná proměnná se střední hodnotou nF(t) a rozptylem nF(t)(1 − F(t)). Z toho plyne, že je nevychýlený odhad funkce F(t).






Někteří autoři používají v čitateli zlomku hodnotu :[4][5]


Střední hodnota
Střední hodnota empirického rozdělení je nestranný odhad střední hodnoty rozdělení populace

která se častěji označuje

Rozptyl
Rozptyl empirického rozdělení znásobený je nestranný odhad rozptylu rozdělení populace

![{\displaystyle {\begin{aligned}\operatorname {Var} (X)&=\operatorname {E} \left[(X-\operatorname {E} [X])^{2}\right]\\[4pt]&=\operatorname {E} \left[(X-{\bar {x}})^{2}\right]\\[4pt]&={\frac {1}{n}}\left(\sum _{i=1}^{n}{(x_{i}-{\bar {x}})^{2}}\right)\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/856a9443ed6145aee944520e94efa625bfadd3bd)
Střední kvadratická chyba
Střední kvadratická chyba empirického rozdělení je
![{\displaystyle {\begin{aligned}\operatorname {MSE} &={\frac {1}{n}}\sum _{i=1}^{n}(Y_{i}-{\hat {Y_{i}}})^{2}\\[4pt]&=\operatorname {Var} _{\hat {\theta }}({\hat {\theta }})+\operatorname {Bias} ({\hat {\theta }},\theta )^{2}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2928ea7b7ebfcad86439fae9b35ad4f576eaabfe)
kde je odhad a neznámý parametr


Kvantily
Pokud není celé číslo, pak -tý kvantil je jednoznačný a jen roven



kde je horní celá část čísla (nejmenší celé číslo větší nebo rovné ).


Pokud je celé číslo, pak -tý kvantil není jednoznačný a jeho hodnota může být jakékoli reálné číslo vyhovující nerovnosti


Empirický medián
Pokud je liché, pak empirický medián je číslo


pokud je sudé, pak empirický medián je číslo

Asymptotické vlastnosti
Protože poměr (n + 1)/n se pro n jdoucí k nekonečnu blíží k 1, asymptotické vlastnosti z obou výše uvedených definic jsou stejné.
Podle zákona velkých čísel odhad konverguje k F(t) pro n → ∞ skoro jistě pro každou hodnotu t:[2]


Odhad je tedy konzistentní. Tento výraz vyjadřuje bodovou konvergenci empirické distribuční funkce ke skutečné distribuční funkci. Silnější tvrzení poskytuje Glivenkova–Cantelliho věta, která říká, že konvergence je stejnoměrná přes t:[6]

Suprémová norma v tomto výrazu se nazývá Kolmogorovova–Smirnovova statistika pro testování, jak dobře empirické rozdělení vyhovuje předpokládané skutečné distribuční funkci F. Mohou být použity i jiné normy, například L2-norma, která dává Cramérovu–von Misesovu statistiku.
Asymptotická rozdělení lze dále charakterizovat několika různými způsoby:
Centrální limitní věta, říká, že bodově má asymptoticky normální rozdělení se standardní rychlostí konvergence:[2]


Tento výsledek rozšiřuje Donskerova věta, která říká, že pokud empirický proces považujeme za třídu funkcí indexovaných reálným číslem , konverguje v rozdělení ve Skorochodově prostoru ke gaussovskému procesu se střední hodnotou nula , kde B je standardní Brownův můstek.[6] Kovarianční struktura tohoto gaussovského procesu je





Rovnoměrnou konvergenci v Donskerově větě lze kvantifikovat výsledkem známým jako maďarské vnoření:[7]

Rychlost konvergence výrazu lze také kvantifikovat asymptotickým chováním suprémové normy tohoto výrazu. V této oblasti existují další výsledky, například Dvoretzkého–Kieferova–Wolfowitzova nerovnost poskytuje meze tail probabilities of :[7]


Kolmogorov ukázal, že pokud je distribuční funkce F spojitá, pak výraz konverguje v rozdělení k , který má Kolmogorovovo–Smirnovovo rozdělení, které nezávisí na tvaru funkce F.

Ze zákona opakovaného logaritmu plyne další výsledek[7]

a

Intervaly spolehlivosti

Podle Dvoretzkého–Kieferovy–Wolfowitzovy nerovnosti lze interval, který obsahuje skutečnou distribuční funkci s pravděpodobností , zapsat




Podle výše uvedených mezí můžeme graficky znázornit empirickou distribuční funkci, distribuční funkci a intervaly spolehlivosti pro různé distribuce pomocí libovolné statistické implementace. Následuje syntax z Statsmodel[nedostupný zdroj] pro grafické znázornění empirického rozdělení.
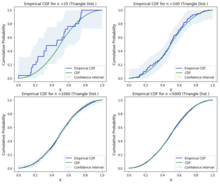
Statistické implementace
K softwarovým implementacím empirické distribuční funkce patří:
- V programovacím jazyce R lze počítat empirické distribuční funkce, k dispozici je několik metod pro grafické znázornění a tisk a výpočty empirických distribučních funkcí.
- V Mathworks lze použít vykreslení grafu empirické distribuční funkce (cdf)
- jmp ze SAS obsahuje CDF plot, který vytváří graf empirické distribuční funkce
- Minitab, vytváří empirické distribuční funkce
- Mathwave Archivováno 29. 7. 2020 na Wayback Machine. umožňuje napasovat rozdělení pravděpodobnosti na data
- Dataplot, umožňuje vykreslit graf empirické distribuční funkce
- Scipy Archivováno 24. 10. 2021 na Wayback Machine., pomocí scipy.stats umožňuje vykreslit graf rozdělení
- Statsmodels, umožňuje použití statsmodels.distributions.empirical_distribution.ECDF
- Matplotlib, umožňuje použití histogramů pro vytvoření grafu kumulativního rozdělení
- Seaborn obsahuje funkci seaborn.ecdfplot
- Plotly, lze použít funkci plotly.express.ecdf
- Excel umožňuje vykreslit graf empirické distribuční funkce
Odkazy
Reference
V tomto článku byl použit překlad textu z článku Empirical distribution function na anglické Wikipedii.
- ↑ A modern introduction to probability and statistics: understanding why and how. London: Springer, 2005. Dostupné online. ISBN 978-1-85233-896-1. OCLC 262680588 S. 219.
- ↑ a b c van der Vaart 1998, s. 265.
- ↑ PlanetMath. planetmath.org [online]. [cit. 2022-04-07]. Dostupné v archivu pořízeném z originálu dne 2021-02-13.
- ↑ Coles 2001, s. 36, Definition 2.4.
- ↑ Madsen 2006, s. 148-149.
- ↑ a b van der Vaart, s. 266.
- ↑ a b c van der Vaart 1998, s. 268.
Literatura
- COLES, S., 2001. An Introduction to Statistical Modeling of Extreme Values. [s.l.]: Springer. ISBN 978-1-4471-3675-0.
- MADSEN, H. O.; KRENK, S.; LIND, S. C., 2006. Methods of Structural Safety. [s.l.]: Dover Publications. ISBN 0486445976.
- SHORACK, G.R.; WELLNER, J.A., 1986. Empirical Processes with Applications to Statistics. New York: Wiley. Dostupné online. ISBN 0-471-86725-X.
- VAN DER VAART, A.W., 1998. Asymptotic statistics. [s.l.]: Cambridge University Press. Dostupné online. ISBN 0-521-78450-6.
Související články
- Càdlàg funkce
- Count data
- Fitting rozdělení
- Dvoretzkého–Kieferova–Wolfowitzova nerovnost
- Empirická pravděpodobnost
- Empirické zpracování
- Kvantil – odhad kvantilů ze vzorku
- Četnost
- Kaplanův–Meierův odhad pro cenzorované procesy
- Funkce přežití
- Q-Q graf
- Znak (statistika)
Externí odkazy
 Obrázky, zvuky či videa k tématu Empirická distribuční funkce na Wikimedia Commons
Obrázky, zvuky či videa k tématu Empirická distribuční funkce na Wikimedia Commons
Portály: Matematika







